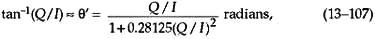Serious consequences can arise when medical equipment is misused, either accidentally or maliciously. Also, the issue of operational and data security is growing increasingly important as system designs become more capable, feature-rich and complex. This is becoming a particularly crucial design factor for products that leverage web connectivity to deliver fast, safe and cost-effective services across the Internet.
To address these issues and also to provide safety features for systems that could potentially be misused, engineers building medical equipment increasingly find it essential to include a security-type device such as a secure IC. They can use robust security solutions to prevent unauthorized devices from being connected to their equipment, protect against ‘man-in-the-middle’ attacks that intentionally modify the data flow between an authorized device and a host system, and control the usage of disposable devices, among other purposes.
A solid M2M (machine-to-machine) authentication solution based on a security IC is essential for any medical system requiring security capabilities. It can ensure safe, normal, uncorrupted equipment operation by providing unequivocal assurance to the embedded control electronics that the system is communicating with a genuine peer system or subsystem, before providing that entity a service or authorizing it to access sensitive data.
The integrity of the authentication service that an M2M solution delivers should also be leveraged whenever the use of the medical equipment requires additional features, such as functions for performing enforcement or applying capability limitations. Of course, the fundamental foundation of tight security that the solution achieves must always be maintained.
Authentication methods use either symmetric or asymmetric algorithmsAuthentication schemes are typically implemented with symmetric algorithms such as the DES and AES types, or with asymmetric algorithms such as the RSA type. These methods are differentiated by the complex mathematical manipulations each uses for authentication. Security ICs can typically process both symmetric and asymmetric algorithms, if necessary.
Symmetric algorithms are often preferred because they use small key sizes that enable quick computations, only a few CPU clock cycles per data block. However, since the same key is used to perform both host and device authentication, it is mandatory that the identity of that key be kept secret, safe from theft or duplication by any means.
Asymmetric algorithms are generally stronger. The process of verifying that a device is genuine requires unique private/public keys pairs per device. The private key is known only to the security IC, and the public key is shared to all. This security scheme uses unique large key size and complex mathematic operations. Thus, the authentication process involves a lot of computation, which has the potential to slow down the security function.
Security ICs typically incorporate a cryptographic (crypto) accelerator that speeds up the algorithm processing. Still, the mathematic operations of asymmetric schemes take longer than those of symmetric ones: milliseconds vs. microseconds for a Secure IC.
However, the robust security protection that asymmetric schemes deliver usually must be executed only a few times during the life cycle of the device or system it protects—such as when the device or system connects or reconnects to an external component or system. Therefore, the computational delay is seldom problematic.
Some applications of asymmetric algorithms exploit the method’s strong authentication capabilities for internal purposes, rather than external tasks. For example, asymmetric keys can provide the strong protection for loading or managing symmetric keys in certain types of secure ICs. In such chips, the combination of these security schemes maximizes the protection that the chip delivers without significantly degrading its performance.
Design solutions vary in requirements and protection delivery
Medical system designers can choose from several ways to implement M2M authentication schemes: * Non-standard, low-security designs built with memory-based authentication solutions—These low-cost, often proprietary solutions are extremely vulnerable to physical attacks because the “secret” key information they require isn’t housed in a tamper-proof device. Also, their key lengths—generally 64 bits—are far shorter than what is required by today’s TDES and AES standards, so they don’t meet the stringent security requirements of medical networks.
* Non-standard, non-robust designs built with software encryption only—Software-only solutions, which require a high-performance main system processor, are vulnerable to abuse because they don’t protect the secret key in a secure and tamper-proof device—a serious vulnerability. Furthermore, if conventional microcontrollers are used to run the algorithms, hackers can easily access the algorithm-processing function and get related data out of it.
* Standards-based solutions built with security-IC technologies—Security-IC solutions provide highly robust hardware protection and cryptographic acceleration. They take advantage of the embedded PKI (Public Key Infrastructure) technologies well proven through their vast global deployment in smart cards. These technologies use standardized types of cryptographic operations such as 3DES (168 bits) and RSA (1024 bits, or the 2048 bits that NIST now recommends). The RSA algorithm, for example, significantly simplifies key management in large systems. The long key lengths and proven tamper-proof IC technology used in security-IC solutions meet FIPS requirements for security-sensitive applications.
Figure 1 summarizes these methods for implementing M2M authentication.  Figure 1. Comparison of security technologies for embedded systems.
Figure 1. Comparison of security technologies for embedded systems.
(Source: Renesas Electronics America Inc.)Security-IC-based solutions offer significant advantages for medical product applications. In particular, they deliver robust hardware protection for safely housing secret and private keys, safeguards that are far superior to those of conventional IC solutions.
Conformance and compliance issues for medical product designsAuthentication solutions for medical equipment must address two important design issues: conformance to the ISO 14971 standard and compliance with HIPAA regulations.
Medical products built using standards-based security-IC technologies can meet all applicable security performance requirements. With regard to ISO 14971, conformant designs can be used to prevent introduction of a counterfeit or unauthorized peripheral from entering the supply chain. Also, they provide a mechanism for insuring that a peripheral cannot be used past a pre-determined useful lifespan.
With regard to HIPAA, compliant medical equipment with robust authentication capabilities can mitigate the risks associated with liability, revenue loss, security breaches, device effectiveness and security-level agreements. Furthermore, the high level of protection provided by the security IC can directly address and resolve issues associated with unfair competition, cost of operation, license and band protection, and credibility with business partners and customers.
Information is shared by
www.irvs.info